数据挖掘算法初识
一、数据挖掘算法概述

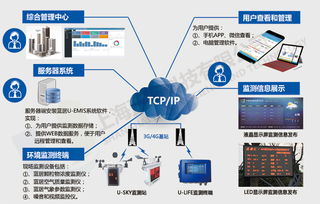
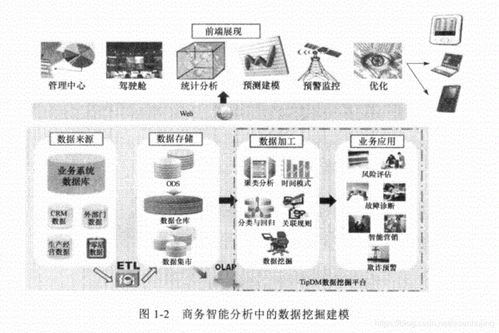
数据挖掘是一种从大量数据中提取有用信息和知识的技术。它通过对数据进行一系列的处理和分析,发现数据中的规律、趋势和模式,为决策提供支持。数据挖掘算法是实现数据挖掘的核心技术,包括关联规则挖掘、聚类分析、分类与预测等。
二、数据预处理

数据预处理是数据挖掘的重要步骤之一,包括数据清洗、数据集成、数据归约和数据变换。
2.1 数据清洗
数据清洗的目的是去除重复、错误和不完整的数据,提高数据的质量和精度。常用的方法包括筛选、填充、修正等。
2.2 数据集成
数据集成是将多个来源、格式和结构的数据整合在一起,形成一个统一的数据集。这个过程中需要注意数据的一致性和完整性。
2.3 数据归约
数据归约是将大量数据压缩成小规模的数据集,同时保持数据集的关键信息。这样可以减少数据的维度和复杂度,提高算法的效率和精度。
2.4 数据变换
数据变换是将数据从一种形式转化为另一种形式,以适应不同的数据挖掘任务和算法。常用的方法包括特征提取、特征选择和特征转换等。
三、关联规则挖掘

关联规则挖掘是发现数据之间的相关性、依赖性和频繁模式的技术。常用的关联规则挖掘算法包括频繁项集挖掘和关联规则挖掘算法。
3.1 频繁项集挖掘
频繁项集挖掘是从大量数据中寻找频繁出现的项集。这些项集可能表示数据中的重要模式和趋势。常用的频繁项集挖掘算法包括Apriori算法和FP-Growh算法。
3.2 关联规则挖掘算法
关联规则挖掘算法是根据频繁项集挖掘的结果,发现数据之间的关联规则。这些关联规则可以表示数据之间的相关性、依赖性和因果关系。常用的关联规则挖掘算法包括Apriori算法和FP-Growh算法。
四、聚类分析

聚类分析是将数据划分为不同的簇或类别,使得同一簇内的数据相似度高,不同簇间的数据相似度低。常用的聚类分析算法包括聚类算法分类、k-均值聚类算法和DBSCA算法等。
4.1 聚类算法分类
聚类算法可以分为层次聚类、密度聚类、划分聚类等。层次聚类是根据数据的层次关系进行聚类;密度聚类是根据数据的密度分布进行聚类;划分聚类则是根据数据的相似度进行聚类。
4.2 k-均值聚类算法
k-均值聚类算法是一种常见的划分聚类算法,它将数据划分为k个簇,每个簇的中心点是该簇所有数据的平均值。该算法通过迭代优化,使得每个数据点到其所属簇的中心点的距离之和最小。
4.3 DBSCA算法
DBSCA算法是一种密度聚类算法,它将数据分为核心点、边界点和噪声点。该算法通过计算任意两个点之间的距离和密度,将相连的核心点划分为不同的簇,同时将边界点和噪声点排除在外。
五、分类与预测

分类与预测是利用已知类别的样本数据,构建分类模型,并对未知类别的数据进行预测和分类。常用的分类与预测算法包括决策树算法、朴素贝叶斯算法和支持向量机算法等。
5.1 决策树算法
决策树算法是一种常见的分类与预测算法,它通过构建一棵决策树,将样本数据划分为不同的类别。决策树的每个节点代表一个属性或决策准则,每个分支代表一个决策结果,最终的叶节点代表一个类别或预测结果。常用的决策树算法包括ID3、C
4.5和CART等。